
Everlaw generates both basic and rigorous performance metrics for predictive coding models. This article will discuss the differences between basic and rigorous performance metrics on Everlaw.
To begin, we will walk through the role of the holdout set, the foundation of predictive coding performance metrics.
Table of Contents
- What is the holdout set?
- How do I generate basic performance metrics for my model?
- How do I see my model's rigorous performance metrics?
- What is the difference between basic and rigorous performance metrics?
- Which documents generate rigorous performance metrics?
- I've reviewed documents in my holdout set, so why don't I see any performance metrics?
- How can I increase the number of documents contributing to my model's rigorous performance metrics?
- Why did the number of documents contributing to my model's rigorous metrics decrease?
- What does performance history look like for rigorous performance metrics?
What is the holdout set?
The holdout set is a randomly sampled 5% of documents from each upload to your project. The holdout set is not used to train your model, but instead is used to generate model performance metrics after a sufficient number of holdout documents have been reviewed. Performance metrics are generated by comparing the predictions your model makes on the documents in its holdout set to how your team reviewed those documents. The more the model's predictions agree with your team's review decisions, the higher its reported performance will be.
How do I generate basic performance metrics for my model?
After you have reviewed at least 400 qualified (i.e., contains sufficient text, unique, and not in conflict) with 100 relevant and 100 irrelevant, initial basic performance metrics will be generated. These initial performance metrics will be based on a sample of documents from the “Reviewed” set. Note that any documents sampled from the “Reviewed” set that are currently being used to generate basic performance metrics will not be used to train the model.
Although initial basic performance metrics give you a general sense of your model’s performance, the sampled documents used to generate these metrics change at every model update. Ideally, performance metrics should be evaluating a consistent set of documents. Reviewing holdout set documents will generate performance metrics based on a consistent set of documents over time and accordingly improve the accuracy of these metrics.
To generate basic performance metrics solely based on reviewed holdout set documents, you should review approximately 200 qualified holdout set documents with at least 50 reviewed relevant and 50 reviewed irrelevant. Unreviewed holdout documents can be found by navigating to the “Holdout set” section under “Performance” and selecting the gray “Review” button. To meet the holdout threshold, reviewed holdout set documents must have sufficient text, be unique (e.g., duplicates of a reviewed document that are coded the same are only counted once), and not in conflict (e.g., emails that have been coded irrelevant in the same thread as emails coded relevant are not considered as qualified reviewed).

Until enough holdout set documents have been reviewed to meet the holdout set threshold (200/50/50), the model will generate basic performance metrics based on a combination of any reviewed holdout set documents and documents sampled from the “Reviewed” set.
How do I see my model's rigorous performance metrics?
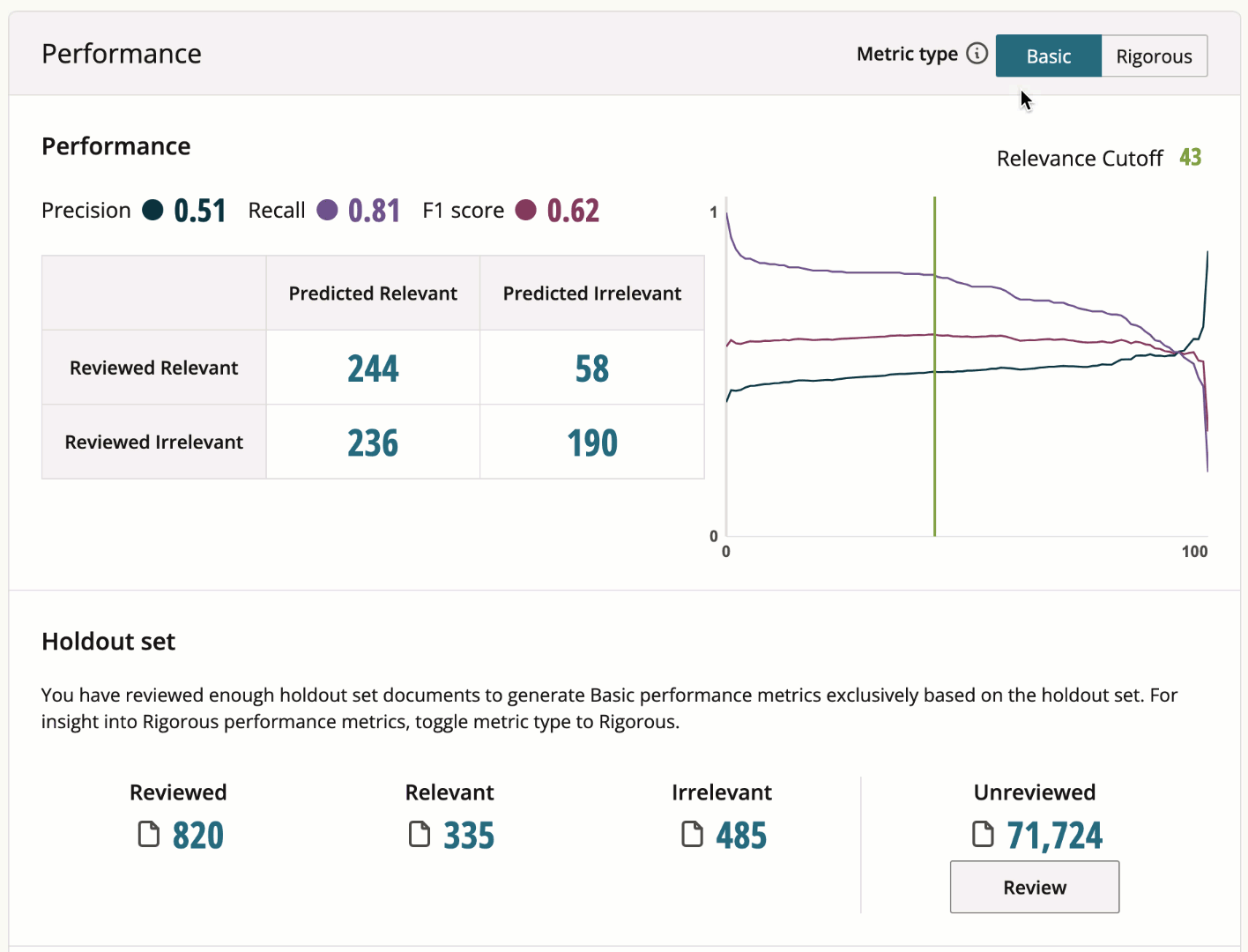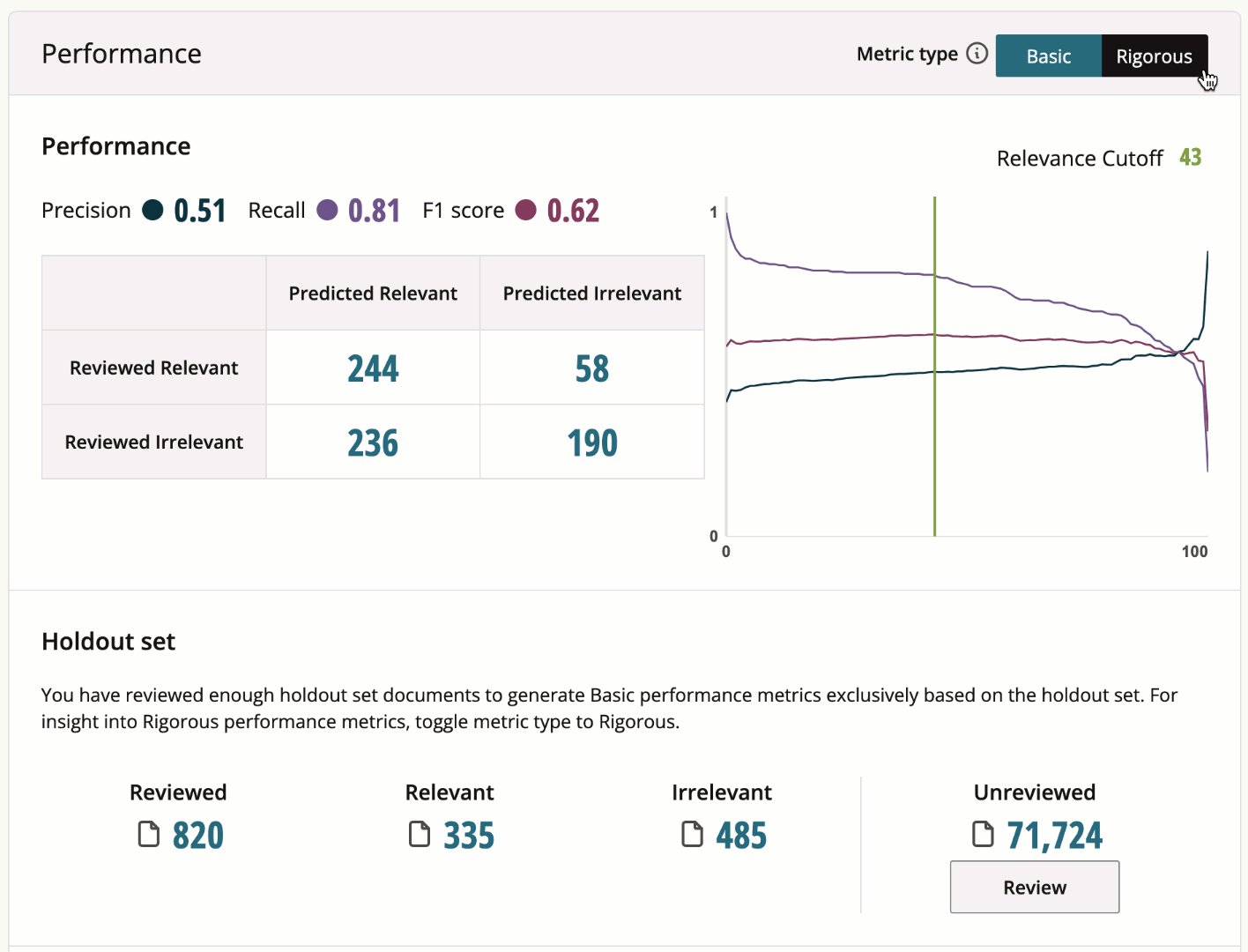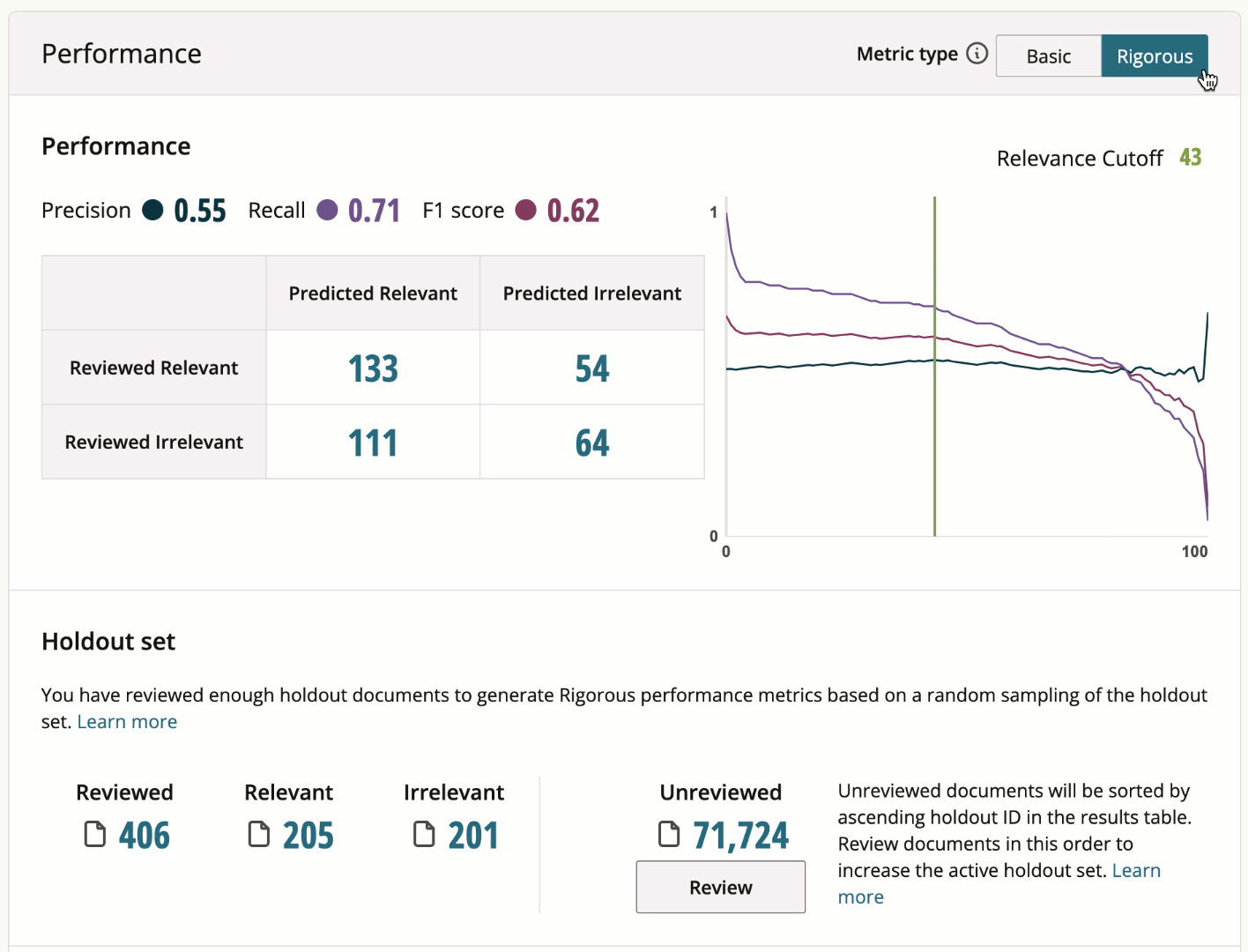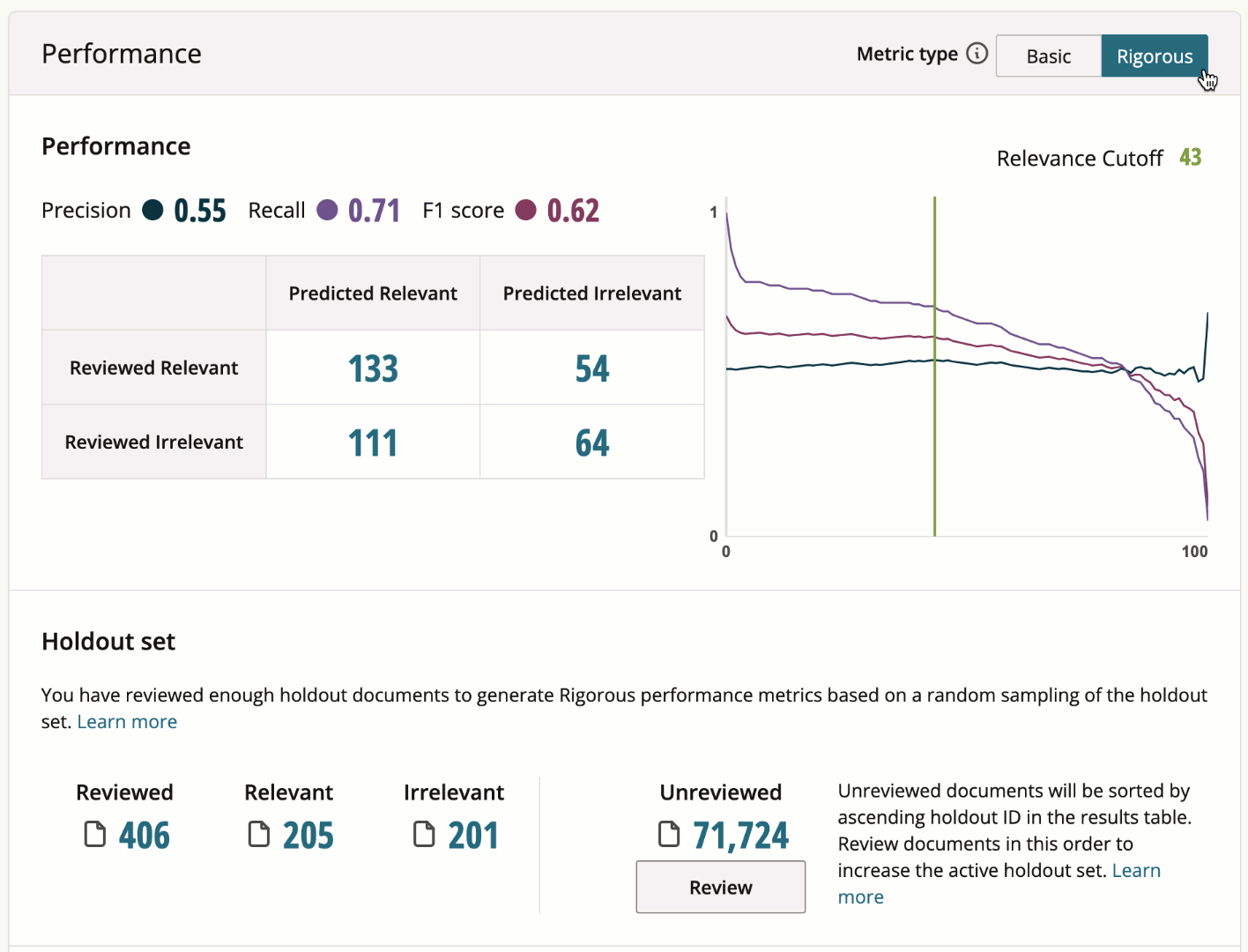
Find your model's rigorous performance metrics in the Holdout Set section of your model's page under the "Performance" section. By default, basic performance metrics are displayed. To switch to rigorous performance metrics, simply toggle your holdout set to Rigorous.
If rigorous performance metrics are not available, your holdout set has not been not been sufficiently reviewed. To generate rigorous performance metrics based on a random sample of reviewed holdout set documents, toggle your holdout set to Rigorous and click the gray “Review” button to start reviewing holdout set documents in consecutive order from top to bottom to meet the rigorous holdout threshold (approximately 200 holdout set documents total reviewed in the order provided with at least 50 relevant and 50 irrelevant). As a reminder, to meet the holdout threshold, reviewed holdout set documents must have sufficient text, be unique (e.g., duplicates of a reviewed document that are coded the same are only counted once), and not in conflict (e.g., emails that have been coded irrelevant in the same thread as emails coded relevant are not considered as qualified reviewed).

What is the difference between basic and rigorous performance metrics?
The difference between basic and rigorous performance metrics is the sample of documents used to generate them. Basic performance metrics may be generated from a biased sample of documents. Rigorous performance metrics are generated from a truly random sampling of a model’s reviewed holdout documents.
To illustrate the difference between basic performance metrics based on all of the reviewed holdout set documents and rigorous performance metrics, let’s imagine this scenario: A team sets up a predictive coding model looking for hot documents. The model needs to be trained on some documents (plus, they need to get started on their case), so they start reviewing documents. To find documents to review in order to train the model, they run searches for documents that contain keywords relevant to their case, as well as documents that come from certain custodians.
The team’s predictive coding model is now running, and basic performance metrics are being generated based on a random sample of reviewed training documents. However, the team wants to generate performance metrics based on a consistent set of documents to track the model’s historical performance, so they begin reviewing holdout set documents. Because they are still trying to find hot documents for their case, they review documents in their holdout set that contain the same relevant keywords, or that come from those certain custodians. After sufficiently reviewing holdout set documents to meet the holdout threshold (approximately 200 qualified holdout set documents reviewed with at least 50 relevant and 50 irrelevant), their model is now generating basic performance metrics based solely on reviewed holdout set documents. The model seems to be performing well!
A potential issue with these metrics, however, is that they are not being generated from a random sample of holdout set documents from the project. The holdout set was created from a random sample of the project’s documents, but the documents that they reviewed, and that therefore generated the model’s performance metrics, were chosen via non-random selection (e.g., running keyword searches, selecting particular custodians). In fact, the non-random selection process used to review holdout set documents was similar to the non-random selection process used to review documents for training. Because of this, the documents that the model used to test its prediction accuracy were likely similar to the documents it was originally trained on. It would therefore be expected that the model’s performance metrics would show it performing well. However, if the model was given a completely random document to make a prediction on, it may perform less well than expected.
As the above scenario illustrates, the documents which generate performance metrics must be randomly selected to prevent inflating your model’s performance. The next section will describe how these documents are selected.
Which documents generate rigorous performance metrics?
Let’s say your project has one million documents in it. Your holdout set, which represents a randomly sampled 5% of your total project, has 50,000 documents in it. Each of these 50,000 holdout documents is assigned a random identifier, known as its holdout ID (HID). Some of these holdout documents have been reviewed, while others have not yet been reviewed. Your model’s rigorous performance metrics are generated from all reviewed holdout documents with lower HIDs than the lowest-numbered unreviewed holdout document.
To illustrate how performance metrics are generated based solely on holdout set documents, imagine that the cells in the table below represent the first fifteen documents in your holdout set, in order of ascending HIDs. HIDs in bolded text represent documents that have been reviewed.
Once at least 200 qualified holdout set documents are reviewed with at least 50 reviewed relevant and 50 reviewed irrelevant, basic performance metrics are generated based on all reviewed holdout documents. In the table below, the documents used to generate basic performance metrics have been shaded beige:
Rigorous performance metrics, however, are generated by the contiguous set of reviewed holdout documents beginning with the lowest-numbered reviewed document. In the table below, the documents used to generate rigorous performance metrics have been shaded green:
Only the documents numbered 96 and 114 are used to generate the model’s rigorous performance metrics. Although document 256 has been reviewed, it will not contribute to the model’s rigorous performance metrics until documents 117 and 204 have been reviewed, as well. This ensures that a random set of documents is used to evaluate the model, providing unbiased metrics.
If you want to increase the number of documents used to generate rigorous performance metrics, you will need to review the lowest-numbered unreviewed holdout documents. To aid your review, toggle your holdout set to Rigorous and click the gray “Review” button to open the list of unreviewed holdout documents from the model page, the holdout set documents will appear in order from lowest to highest HID. You can simply review the list of documents from top to bottom.
I have reviewed documents in my holdout set, so why don’t I see any performance metrics?
In order for your model to begin generating basic performance metrics based solely on your reviewed holdout set documents, you need to review approximately 200 qualified holdout set documents, 50 of which have been reviewed as relevant, and 50 of which have been reviewed as irrelevant.
In order for rigorous performance metrics to be generated, the contiguous set of reviewed holdout documents must meet these same criteria. In other words, when ordered by ascending HID, the first 200 documents in your holdout set must all be reviewed at least, with approximately 50 deemed relevant and 50 deemed irrelevant.
How can I increase the number of documents contributing to my model’s rigorous performance metrics?
If you want to increase the number of documents used to generate rigorous performance metrics, you will need to review the lowest-numbered unreviewed holdout documents. This is because your holdout subsample will exclude any holdout documents above the lowest-numbered unreviewed document. To aid your review, toggle your holdout set to Rigorous and click the gray “Review” button to open the list of unreviewed holdout documents from the model page, the holdout set documents will appear in order from lowest to highest HID. You can simply review the list of documents from top to bottom.
Why did the number of documents contributing to my model’s rigorous metrics decrease?
Uploading new documents to your project may cause the number of documents contributing to your model’s rigorous performance metrics to fluctuate. This is due to five percent of the newly uploaded documents being randomly selected for the holdout set and assigned HIDs. If any of these newly uploaded documents are assigned a lower HID than any of the documents already in the contiguous set of reviewed documents generating rigorous metrics, those higher-numbered documents will no longer contribute to your model's rigorous metrics until the lower-numbered unreviewed holdout set documents have been reviewed. This ensures that your model continues to generate performance metrics based on a random and representative sample of documents from your project.
What does performance history look like for rigorous performance metrics?
Your model’s rigorous performance history graph will reflect the performance of your model at each point in time that the holdout set threshold was met. This will generally mean that the same core set of documents (though the set may grow) will be used to generate each data point on your performance history graph. New uploads to your project may cause a separate set of holdout documents to be used. If the holdout threshold was not met at a given model update, there will be no data for that date. You can view the number of documents contributing to your performance metrics over time by viewing the Holdout Size graph under Performance History.