
To view all of Everlaw's predictive coding-related content, please see our predictive coding section.
This article will help you understand how to kick off your predictive coding model and walk through the high level workflows of leveraging your model’s results.
For an introduction to predictive coding, feel free to reference our beginner’s guide to predictive coding.
For an overview of how to create a predictive coding model, see our article about creating and editing a predictive coding model.
Generating initial prediction scores
In Everlaw, a predictive coding model will start to generate prediction scores after 200 qualified documents have been reviewed with at least 50 relevant and 50 irrelevant pursuant to the model’s criteria.
Documents are considered qualified if they:
- have sufficient text,
- are unique (e.g., if there are duplicates of a reviewed document that are coded the same, only one of those documents is considered as qualified reviewed), and
- are not in conflict (e.g., emails that have been coded irrelevant in the same thread as emails coded relevant are not considered as qualified reviewed).
Prediction generation progress
Predictive coding models that have not yet generated prediction scores will have a section titled “Prediction generation progress” at the top of the given model page indicating progress towards the training threshold.

“Review progress”
- Displays progress bars indicating how many qualified documents have been reviewed and how many additional documents need to be reviewed to meet the training threshold. As you review documents according to the model’s criteria, the progress bars under this section will update and track your model’s progress towards the training threshold.
“Recommended to do next”
- Provides you with an easy way to find additional qualified documents to review. Simply click the “+ New Training Set” button under the “Recommended to do next” section, enter a name for the training set and choose to create the training set from a randomized set of documents from across the entire project or seeded from a recent/favorite search.
For datasets that have low richness or prevalence (i.e., only a small percent of documents in the dataset would be considered relevant), we recommend creating a training set that is seeded from a targeted search to increase the likelihood that examples of relevant documents will be found within the training set.

After your newly created training set is generated, it will appear under the “Recommended to do next” section and you can click the “Review” button to open the results table then start reviewing.
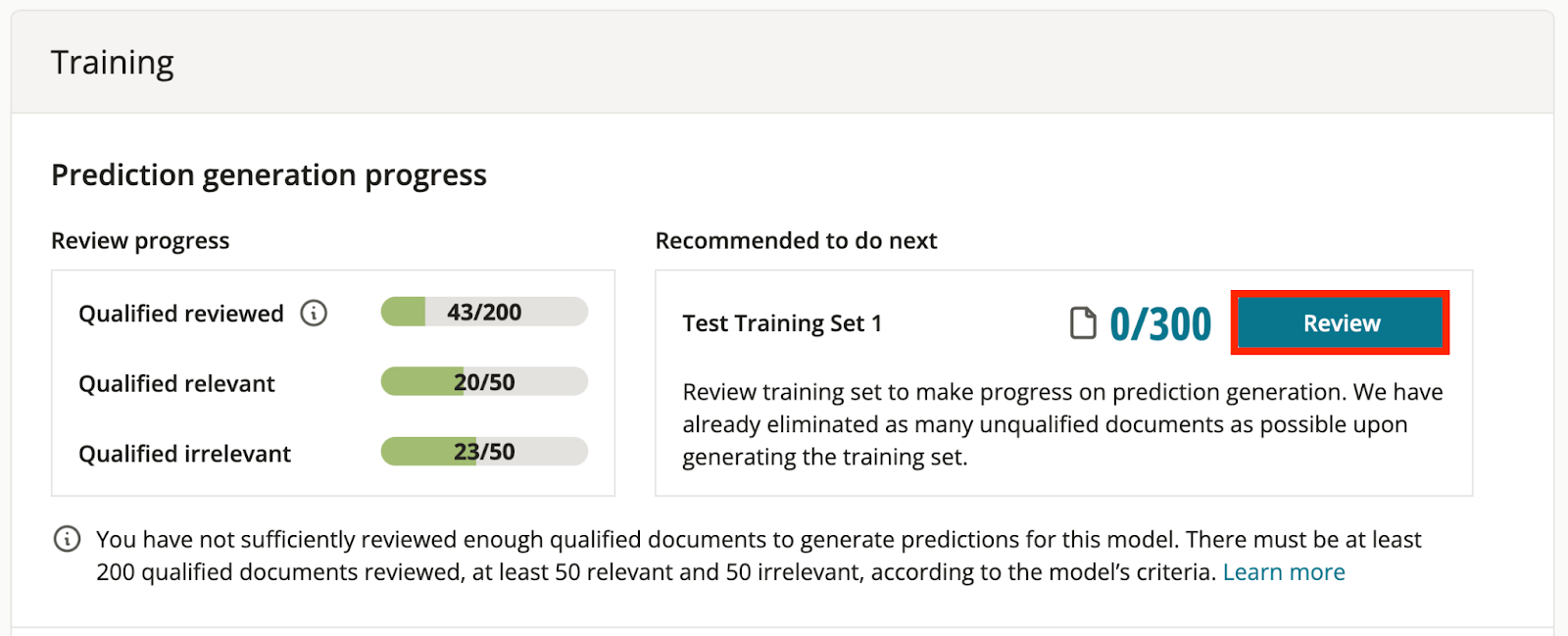
Once 200 qualified documents are reviewed pursuant to model criteria (with at least 50 relevant and 50 irrelevant) to meet the training threshold, return to the model’s page to confirm that the progress bars are displayed as complete and the “Recommended to do next” section indicates that the model has been automatically queued for update. Once the model updates, initial prediction scores will be generated.

Next steps after generating initial prediction scores
Generate initial performance metrics
Your model’s performance metrics measure the recall, precision, and F1 score of your model.
- Recall: estimates what percentage of the relevant documents in your project your model is finding;
- Precision: estimates what percentage of the relevant documents your model finds are actually relevant; and
- F1: calculates the optimal balance of recall and precision.
The model will start generating performance metrics once at least 400 qualified documents are reviewed in total with at least 100 relevant and 100 irrelevant. This means that, while your model will generate prediction scores after you have reviewed 200 qualified documents with at least 50 relevant and 50 irrelevant, you must review an additional 200 documents (with at least 50 relevant and 50 irrelevant) to generate basic performance metrics.
At this threshold, the statistics will be generated based on a sample of documents from the “Reviewed” set. Note that any documents sampled from the “Reviewed” set that are currently being used to generate Basic performance metrics will not be used to train the model.
Although initial basic performance metrics give you a general sense of your model’s performance, a consistent set of documents is not being used to track model performance because the sampled documents used to generate these metrics change at every model update. However, reviewing holdout set documents will allow you to generate performance metrics based on a consistent set of documents over time and accordingly improve the accuracy of these metrics. To generate Basic performance metrics solely based on reviewed holdout set documents, you should review approximately 200 holdout set documents with at least 50 reviewed relevant and 50 reviewed irrelevant. Unreviewed holdout documents can be found by navigating to the “Holdout set” section under “Performance” and selecting the gray “Review” button.

Note that if some holdout set documents have been reviewed but not enough to meet the holdout set threshold (200/50/50), the model will generate Basic performance metrics based on a combination of any reviewed holdout set documents and documents sampled from the “Reviewed” set.
To generate Rigorous performance metrics based on a truly random sample of reviewed holdout set documents, toggle your holdout set to Rigorous and click the gray “Review” button to start reviewing holdout set documents in consecutive order from top to bottom to meet the rigorous holdout threshold (approximately 200 holdout set documents total reviewed in order provided with at least 50 relevant and 50 irrelevant).

Learn more about Basic and Rigorous performance metrics here.
Finding more relevant documents to review
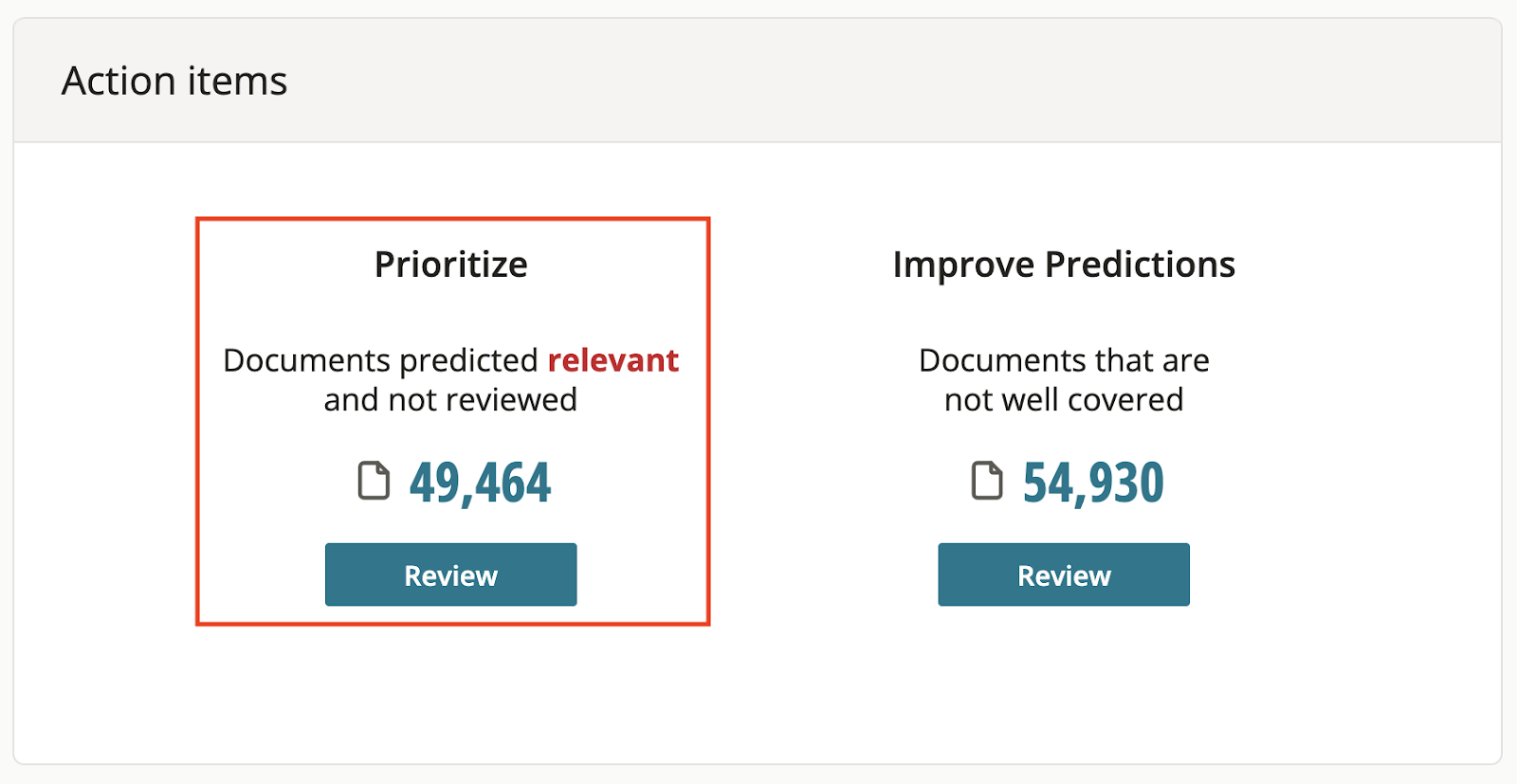
Once the initial prediction scores for your model are generated, you can start to prioritize your review of documents. The “Prioritize” action item will identify documents that your model predicts to be relevant based on your training so far. If your model has generated initial prediction scores but has not yet generated performance metrics, the “Prioritize” action item will identify unreviewed documents with prediction scores of 90 or above. Once your model generates performance metrics, the “Prioritize” action item will point you to unreviewed documents with prediction scores equal to or greater than the relevance cutoff associated with the max F1 score.
In addition to the “Prioritize” action item, you can leverage the distribution graph under “Results” to see the documents in your project along a scale of predicted relevance. To the far left, you can see the documents that have a prediction score of 0. The model predicts that these documents are very unlikely to be relevant. To the far right, there are documents that have a prediction score of 100. The model predicts that these documents are very likely to be relevant.
On the distribution graph, the green flag represents a draggable threshold that can be moved to the left or the right on the distribution graph to understand the number of documents above or below a given prediction score cutoff. By default when your model has generated prediction scores but has not generated performance metrics yet, the green flag appears at the prediction score of 50. Once your model generates performance metrics, the green flag by default will be aligned with the max F1 score (i.e., purple flag).
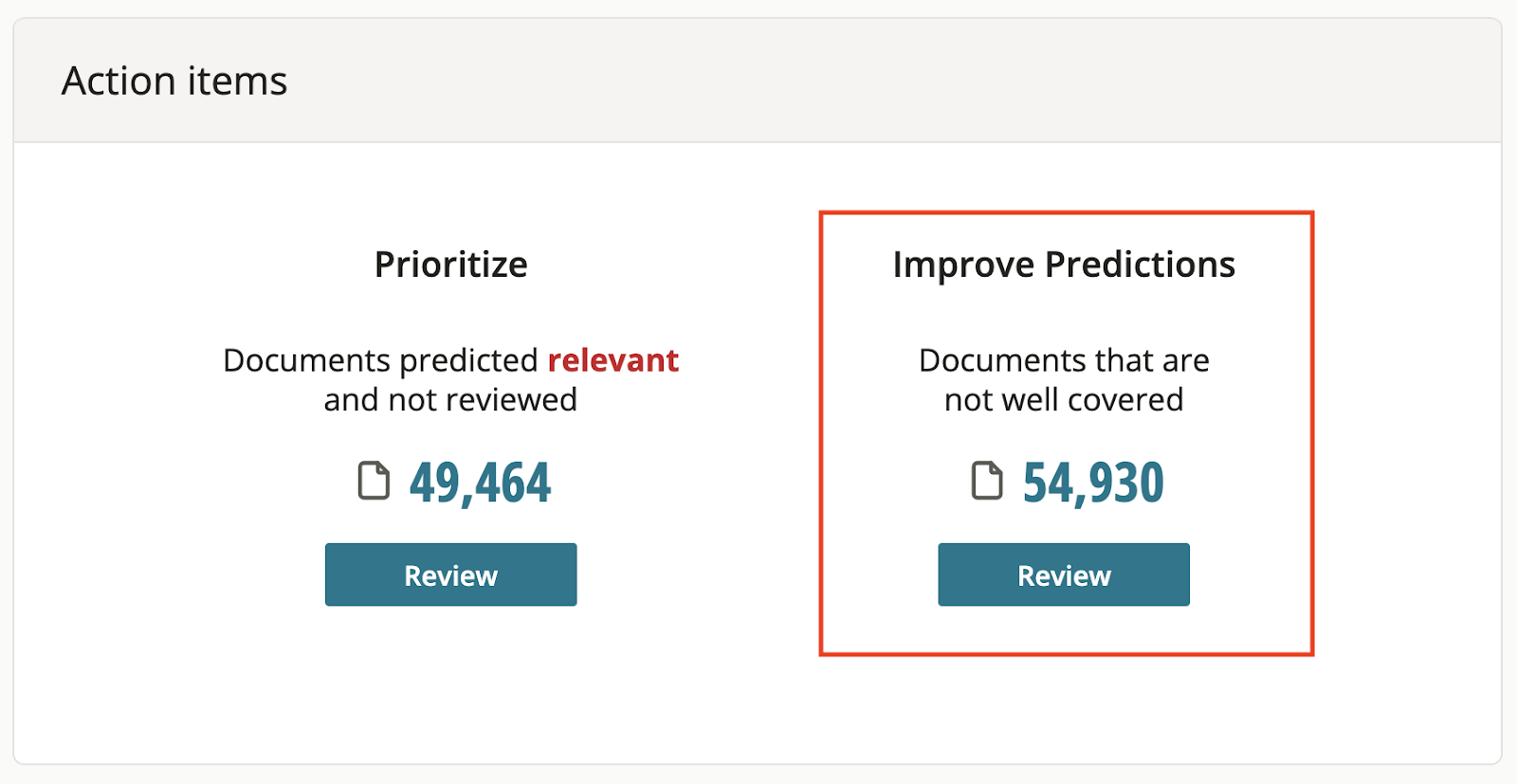
Improving your model’s predictions
The “Improve your Predictions” action item will help you easily find documents that are not well covered in your training set (i.e., documents with a coverage score of 20 or below).
You can also use the coverage map, located at the bottom of your model’s page under “Coverage” in the Training section, to see the coverage scores for all of your documents. Learn more about coverage here.
Once your model generates performance metrics, the “Assess Conflicts” action item will identify any conflicts the model has run into which can be reviewed to improve model predictions. Specifically, this action item is for documents that the team has reviewed but the team's review work conflicts with the model’s predictions for the document. For example, any documents that fall into the following two categories are identified: (a) documents that the model predicts are relevant but have been reviewed as irrelevant and (b) documents that the model predicts are irrelevant but have been reviewed as relevant.
Learn more about interpreting your predictive coding model here and improving your predictive coding model here.