
Use Search settings to make sure your search results include the precise set of documents you plan to review. Search settings has options to specify how to treat duplicate documents, whether you'd like to group attachment families or other document groups together, and if there are any documents within a group that you'd like to exclude from your results. When you specify these options, your search results include all the documents you need and none of the ones you don't.
This article describes each option available in Search settings and how to make use of them.
All users are able to use search settings; no specific permissions are required.
Introduction to Search settings: deduplicate, sample, group, or remove search hits
Once you've constructed your search query, you can use Search settings to deduplicate, sample, group, and remove document hits that are returned by your query. Use these settings to build highly specific searches or run sophisticated search workflows. Visit the Example search workflows using search settings section below for more on these workflows.
Search settings can be applied independently to each logical search container in your query, as well as to the query as a whole. With the exception of deduplication, which is only available for the entire query, you can apply any search combination of settings to any logical container.
Select Search settings to access the Search settings dialog. From here, you can select any combination of up to four different settings. The effect of each setting is reflected below each section as a positive or negative number, indicating the number of document additions or removals resulting from the setting. If there is no effect on your search, the section says No Change.
Select Show walkthrough of your search settings to see a step-by-step visual walkthrough of how your settings modify your search results.
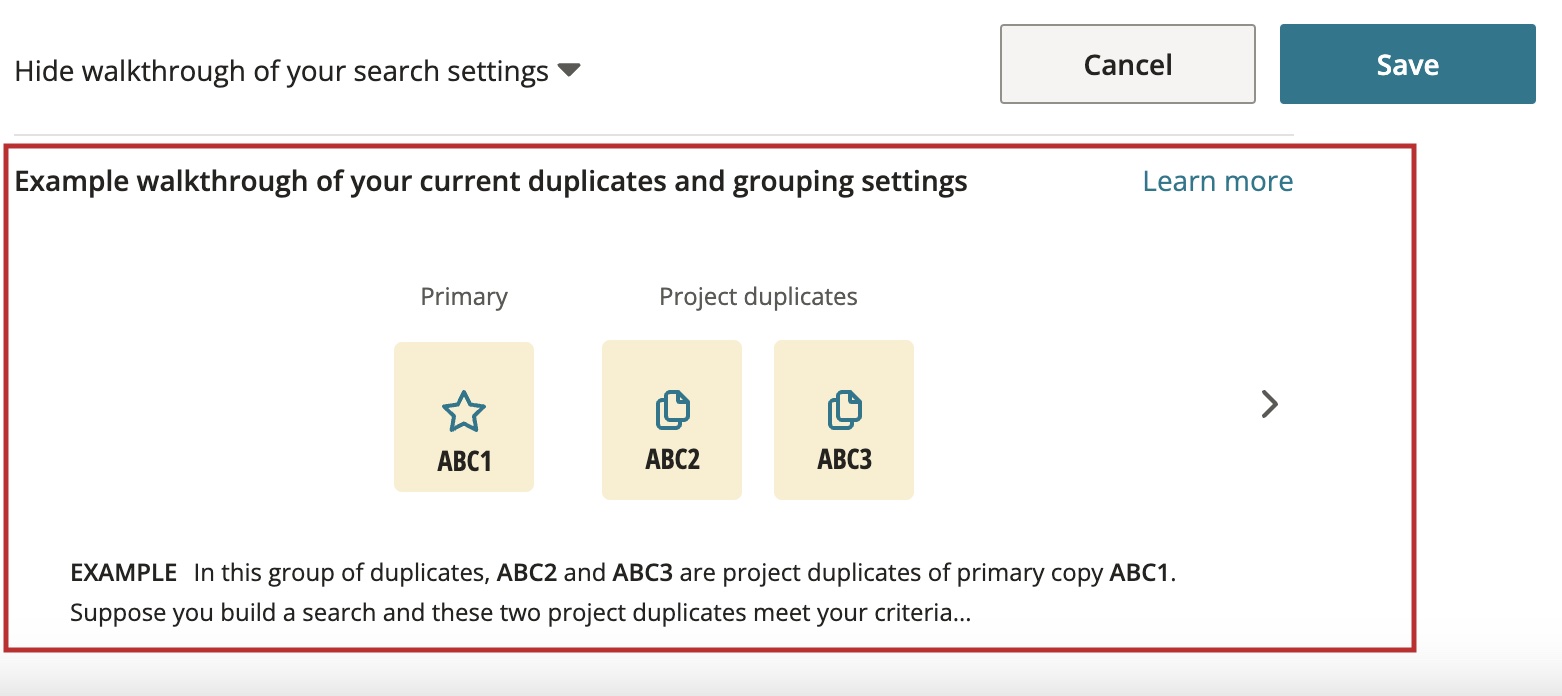
Once you’re happy with your settings, select Save. A summary of applied settings is shown below the search container.

The following sections describe each of the four sections within the settings dialog.
Deduplicate among search hits
Deduplication removes duplicates to ensure that only one document from a duplicate group is returned within your search results. For exact duplicates, the version with the lowest Bates/control number is returned, which is equivalent to the earliest copy uploaded to the platform. For a conceptual overview of deduplication on Everlaw, visit this help article.
If email threading deduplication is turned on in your project, deduplication includes both exact and email duplicates.
If email threading deduplication is turned off, only exact duplicate families are used.
To learn more about this setting, please visit this help article on administrator deduplication settings.
Hide all project duplicates
Your project may have a project-wide setting enabled that hides all non-primary documents in a duplicate family group by default. If so, the search settings tab says Hide All. To learn more about the effects of this setting, please see this help article.
To override this default setting for individual searches, select Search settings and select a different deduplication setting.

Deduplicate within search hits versus project deduplication
This section describes when deduplication happens for these two options, and how each option impacts results.
- Deduplicate within search hits is a search-wide setting. First, Everlaw identifies all documents that match your search criteria. Then, it removes duplicate copies of documents from the search results, leaving only a single copy of each document in your result set.
-
Hide all project exact duplicates is a project-wide setting that identifies duplicates before evaluating your search criteria. If you hide all project exact duplicates, any document flagged as a project duplicate is excluded from search results, regardless of the search criteria.
If the setting to combine email dupes with exact dupes is turned on, this option covers both project exact and email duplicates. For documents that are not emails, only the primary document in the duplicate family (ie. the earliest of the exact dupes uploaded to the platform) is returned in the results, as described above. For emails, the most “complete” version of the email duplicates, as determined by text, metadata, and attachments, is returned. For more information on hiding project duplicates and email threading deduplication settings, please see this article on admin deduplication settings.
Tip
We only recommend using hide project duplicates if you are running a series of searches and want to ensure that two different copies of the same document are never returned across the union of your searches.
This example describes how these two settings affect search results differently. Imagine that you have a project with three exact duplicates (not emails) and no other documents:

Because documents #2.1 and #3.1 are ingested after document #1.1, they are identified as project duplicates. For the following searches:
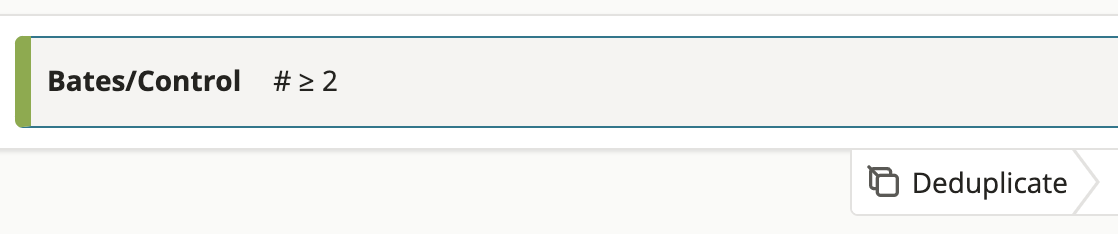
- Search for all documents with control numbers that are 2 or greater, then deduplicate the search results
- This search returns document #2.1, because it has a lower control number than document #3.1
- Search for all documents with control numbers that are 2 or greater and hide project duplicates
- This search returns no results, because both #2.1 and #3.1 have been "hidden" from the search

-
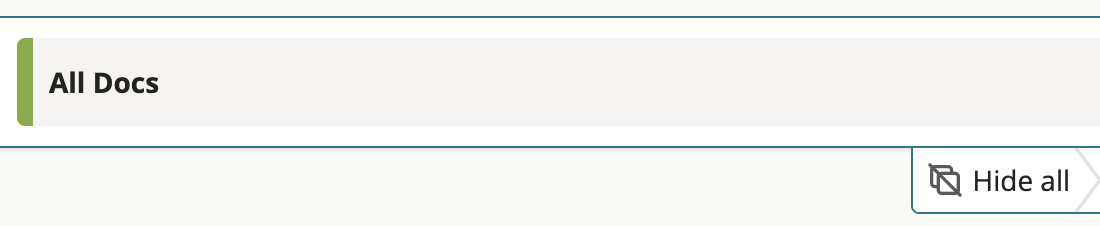
Search for all documents and hide project duplicates
- This search returns document #1.1, because it is the only document that is not "hidden" from the search
Sampling
In the Sampling section, you can choose to keep only a randomly sampled subset of your original document hits. This field accepts a max Sample size (the maximum number of documents in the sample set).
Sampling lets you quickly triage a set of documents or to train predictive coding models. You can also use it to train prediction model with randomly sampled subsets of documents, which may help improve the generated prediction scores.
Document sampling is always applied after deduplication, and before grouping or filtering. This prevents partial email threads from appearing in your results table. Use the document counts below each setting and the search walkthrough at the bottom of the dialog to better understand how these settings impact your final results.
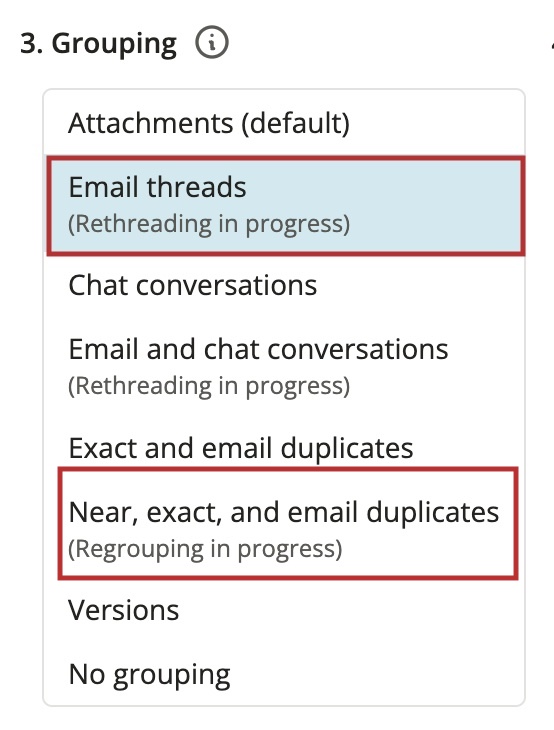
Grouping
Grouping allows you to organize your search hits by context:
- Attachments: Documents in an attachment family. Includes the parent document, often an email, and its attachments.
- Email threads: Emails that comprise an email thread, including replies, reply all, and forwarded emails. Grouping by email thread also includes attachments and both exact and email duplicates.
-
Chat conversations: Chat documents and attachments that collectively represent a complete chat conversation. Examples of a complete chat conversation include all SMS texts collected between two individuals and all the chats collected from a given chat space or room.
- Note: Chat conversation grouping is only available for data uploaded after Release 104 (February 27, 2024 for AU customers and March 1, 2024 for all others). Native chat data uploaded prior to this release can be reprocessed to work with grouping functionality. The original container file for a chat must be reprocessed, not the individual chat files. Processed chat data can be mapped to the fields used for grouping following the steps outlined in this article.
- Email and chat conversations: Group results by both email threads and chat conversations (see above for information on each)
- Exact or Exact and email duplicates: Duplicate copies of the document. If email threading deduplication is turned on in your project, the grouping is by exact and email duplicates; if turned off, the grouping is by exact duplicates only. A complete definition of duplicates is in this article.
- Near duplicates: Documents that are in the same near duplicate group based on textual similarity. By default, exact and email duplicates are included in near duplicate grouping. Please see this article on changing the duplicate inclusion criteria for near duplicate groups. To compare differences across your near duplicate group, use Difference Viewer.
- Versions: Versions of the same document. Most often this includes produced and pre-produced versions, but can also include translated and untranslated versions, etc.
Grouping pulls documents into your search results, even if the documents do not meet your search criteria. For example, an email might be returned by a contents search for "fraud." If you group by email thread, the search results include all the documents in the same email thread, even those that don’t contain the word “fraud."
Grouping is always applied after deduplication and sampling, but before removal. Documents removed during the deduplication step may get reintroduced if they are part of the context that you are grouping by. For example, if you group by duplicates, your search results contain duplicates even if you applied the deduplicate within search setting.
Note: You may see a Rethreading in progress warning when grouping by email thread, or a Regrouping in progress warning when grouping by near duplicate groups. This indicates that email threads or near duplicate groups in your search may be incomplete or misrepresented until the associated rethreading and regrouping tasks are complete. To learn more about email rethreading and near duplicate regrouping statuses, visit this article.
Remove from group
If you have selected a document grouping, Remove from group allows you to remove certain classes of documents from your search results:
-
Parent: The topmost member in a document grouping, such as the primary email to which other documents are attached.
- Note: You cannot remove parents when grouping by email thread. This is to ensure that attachments are not displayed without their associated email parents in the results table.
- Note: For documents grouped by near duplicates, the parent of the near duplicate group is the document with the lowest Bates or control #. For more information on near duplicates, please see this article.
- Children: Any documents that are not the parent in a group, such as email attachments or non-primary duplicates.
- Attachments: Any documents that are considered attachments to another document in the result set. This option is available when grouping by email thread or chat conversation.
- Search hits: Any document that would be returned by your search, after search deduplication is applied.
- Grouped non-hits: All documents that are not designated as a search hits, but introduced via grouping.
- Email duplicates: This option is only available if email threading deduplication is turned on in your project and you group by exact and email dupes. This removes all email duplicates of the primary email in the email dupe family, leaving only exact duplicates of the primary email. The primary email is the version of the email that Everlaw determines is the most complete, based on text, metadata, and attachments.
-
Non-inclusive emails: You can only select this removal option when you group by email threads. Inclusive emails are the minimum set of emails that creates the most complete email content in the thread. This set might comprise one email that is inclusive of all the thread's content, or it might comprise multiple emails that together create the set. Often it comprises only the last email in the branch, and all previous emails appear in the body of that document. Removing non-inclusive emails means the search results only include emails that are not duplicates within the email thread, and are inclusive; attachments are included if their parent email is included. Everlaw considers text, recipients, and attachments to determine inclusiveness.
Tip
For both searches and STRs, Combine email duplicates with exact duplicates in deduplication, grouping and auto-code should be enabled in Project Settings when grouping by email threads and removing non-inclusive emails. If this setting is not enabled, you may receive an error. This setting can be enabled by an Organization Admin under Project Settings > General.
Removal is always applied after the other settings in search settings. You can use the document counts below each setting and the search walkthrough at the bottom of the dialog to better understand how these settings impact your final results.
Regardless of your removal settings, you can use the context panel in the review window to see other documents in each email thread, including duplicates and non-inclusive emails.
View your search and adjust search settings in the results table
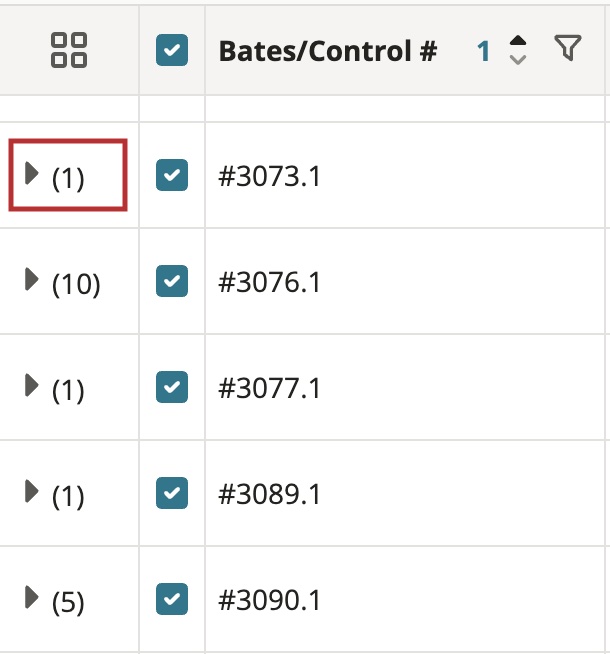
You can view grouped documents and adjust search settings directly from the results table.
Grouped documents are collapsed by default and indicated by a caret next to the parent document. The total number of children in a document grouping is displayed in parentheses (in the case of email threads, only other children and duplicate emails are included in the count, though related attachments are grouped within.
Select the expansion button to expand all or collapse all document groups.
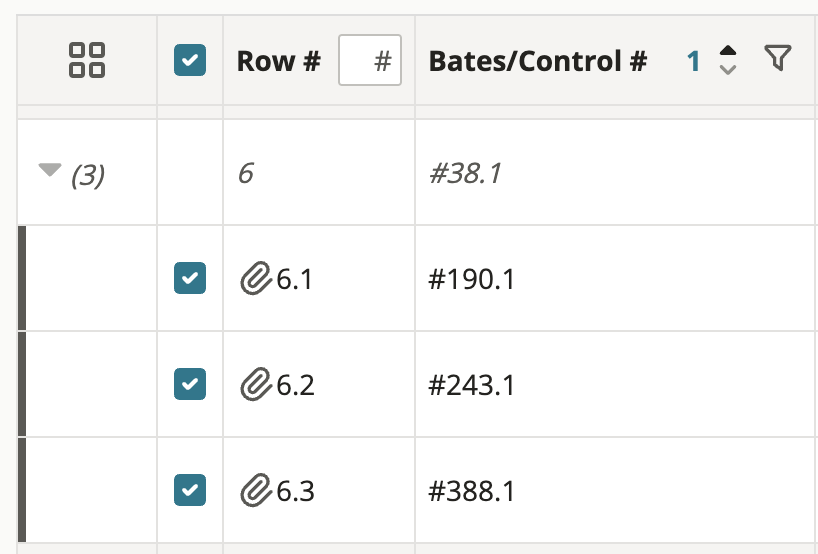
Child documents in a group include row numbers that follow their parents, with decimals appended. In this example, the parent document #11.1 is row 1 and its children are represented in rows 1.1 and 1.2:
If your search settings remove parents from your results, either on the search page or results table, the parents are grayed-out, with children visible under them. The parents are not affected by any export, batch modify, or production actions. As you move through documents in the review window, grayed-out documents are skipped.
To adjust your previously applied search settings, select Settings in the results table toolbar. This opens the same dialog as Search settings, with your applied settings selected. If you change your settings, the results table updates to include the selected settings. This modification results in a new search, as opposed to an update to the original search. As a result, the new search is saved as a separate card on the homepage.
Example search workflows using search settings
Below are some use cases for using search settings. In these examples, you need to use settings for multiple containers and/or multiple settings within each container.
Ensure reviewers are assigned full email threads
You can use search settings to ensure that your search includes entire email threads. This can give you peace of mind that, when creating assignments, you include all emails in a thread for review.
Required permissions: Create or Admin on Assignment Groups
To assign all emails from a given custodian, grouped by email:
- [Optional] Use the Type search term to specify emails.
- Use the Type term if you want your search results to only include emails and their attachments.
- Use the Custodian search term and specify the custodian whose documents you want to assign.
- Select Search settings. This opens the search settings dialog.
- Under Grouping, select Email threads.
- Select Save. This closes the dialog.
- Select Search. This takes you to a results table of the documents.
- From the results table, select Batch > Assign to assign the documents.
Email thread grouping will be respected in your assignment, and when possible, individual threads will be kept together and assigned to one user.
Identify all non-primary duplicate documents to delete
Important
Note that this workflow is only recommended if you've carefully considered the consequences and implications of performing a mass deletion of project documents identified to be duplicates. If you have questions or uncertainties, we encourage you to reach out to support@everlaw.com for help and guidance.
Required permissions: Delete or Database Admin
You can save on storage costs by deleting all duplicate documents in your database. To identify all duplicate documents:
- Select View all documents on your homepage. This takes you to a results table of all your documents
- Select Edit to get to the query builder:
- Select Search settings. This opens the search settings dialog. Ensure that all project duplicates are shown.
- Under Grouping, select Exact and email duplicates or Exact duplicates.
- The grouping option depends on the settings in Project Settings
- For Remove from group select Parent.
- Select Save. This closes the dialog.
- Select Search. This takes you to a results table with the documents.
The document set that results from this search is all duplicate copies of documents in your project. You can delete these documents to remove duplicates.
Important
There are a few things to be aware of before deleting these documents:
-
Duplicates are identified by data intrinsic to documents, but there may be important extrinsic data that Everlaw generates upon processing that you lose when deleting duplicates in this way. For example:
- A duplicate document can belong to different custodians and be found in different file paths. If you delete all duplicates, you may also lose non-duplicative information about custodians and file paths.
- Global deduplication takes into account the attachment group (the document must be duplicative within the context of its attachment group to be deduplicated), deleting duplicates in your database after the fact may result in loss of document context. Generally, if you care about knowing which emails documents were attached to, and vice versa, you should not indiscriminately delete duplicate documents using this workflow.
- This workflow is not recommended for deleting emails from your database, particularly if you have email threading deduplication turned on in your project. To learn more about email threading deduplication, see this article. While our email threading deduplication is robust, there are some situations where non-duplicative emails are mistakenly identified to be duplicates by Everlaw. Bulk deleting emails could cause you to inadvertently remove unique emails from your database.
Pre-production QC
You can use search settings to perform QC on your responsive documents before producing them. This example shows how to ensure that you aren’t producing any privileged documents.
- First, add an extra AND operator into your query builder.
- Within it, select the Coded term and choose your responsiveness code.
- Select Search settings. This opens the search settings dialog.
- For 3. Grouping select Attachments
-
Select Save. This closes the dialog. Your search should look like this:
- Select the outer AND container, and select Search settings.
- Choose the Coded term again and select your Privilege code or category. Then negate it. Your search should look like this:
- Select Search. This takes you to a results table of the documents.
This search identifies documents marked for production, including attachments, that have not been coded for privilege. This allows you to check for coding inconsistencies before running a production and assign them for review.
For additional information on running pre-production QC, see the Pre-Production Workflow Guide and Best Practices article.
Identify the (parent) email and all of its attachments
To find the first email in each email thread of an upload, as well as its attachments:
- Add an extra AND operator into your query builder.
- Within it, select the Uploaded search term and choose the upload you’d like to search for.
- Select Search settings. This opens the search settings dialog.
- For 3. Grouping, select Email threads.
- For 4. Remove from group select Children.
-
Select Save. This closes the dialog. Your result includes the parent documents, or the top email, for every email thread in our upload.
- Select the outer container, then select Search settings. This opens the search settings dialog.
- For 3. Grouping, select Attachments.
- Select Save. This closes the dialog.
-
A good way to double-check the logic of your search is via the instant search preview. The gray bar displays the order of operations conducted in your search. We can interpret this search as the parent emails in threads in our upload, as well as the parent emails’ attachments.
- Select Search. This takes you to a results table of the documents.
Identify all non-inclusive emails
An additional way to save on storage costs is to remove non-inclusive emails from your database. This workflow is accomplished in three parts. First, search for all emails grouped by thread. Then, search for inclusive emails. Finally, combine those searches together and search for all emails grouped by thread, and not the inclusive ones.
- First, start by searching for emails grouped by thread. Add the Type term, and select Email.
- Select Search settings. This opens the search settings dialog.
- For 3. Grouping select Email threads.
- Ensure that you’ve chosen to show all duplicates, then select Save. This closes the dialog. Your search should look like this:
- Select Search on the search page. This takes you to a results table of all emails on your project, grouped by thread (including their attachments). It also saves your search to be used in the next step.
- Create the second component of the search, which is "all emails that are inclusive." Since most settings in the previous search can be reused, you don’t need to create a brand new search. Select the caret button next to your search title and select View version history.
- Select the three-dot menu and select Make a copy of this search.
- Select Settings in the results table. This opens the search settings dialog.
- In 4. Removal, select Non-inclusive emails. Then select Save. This returns all inclusive emails because you removed the non-inclusive ones.
- The final step is to find all emails, grouped by thread, that are non-inclusive. Select the magnifying glass
in the navigation bar to start a new search.
- Add the Prior Search term and select the initial search you created: Type Email, including duplicates, grouped by email threads.
- Add Prior Search again. Select the second search: Type email grouped by email threads without non-inclusive emails.
- Negate the second search by clicking the term to turn it red. Your search should look like this:
- Select Search. This takes you to a results table of these documents. The way to interpret this search is all emails grouped by thread, but NOT the inclusive ones.
Identify all standalone documents (no attachments)
Standalone documents are documents that do not contain attachments. To search for standalone documents:
- Select the Attachment Group Size search term.
- Enter the number 0 in the term’s maximum field.
This searches for all documents with an attachment group size that is less than or equal to 0. - [Optional] Select Search to open a results table.
Identify all emails with no replies
The following search identifies emails that are not part of an email thread. This workflow requires three separate searches that build onto one another using the Prior Search search term.
Step 1: Search for only emails that are children
- Go to the Search page.
- Select the Type search term, and choose the Email value.
- Select Search settings, This opens the Duplicates, sampling, and grouping settings dialog.
- In the Grouping field, select Attachments, and in the Remove from group field, select Parent.
Note
The two other fields — Duplicates among search hits and Sampling — can be left as is.
- Select Save. This closes the dialog.
- Select Search to open the search in a results table.
- Select the title of this search, and rename it "Child Emails".
Step 2: Search for parent emails with no children
- Return to the Search page.
- Select the Prior Search term, and choose your prior search: "Child Emails."
- Select Search settings. This opens the Duplicates, sampling, and grouping settings dialog.
- In the Grouping field, select Email threads to group the search by email thread. This brings in the email thread of those child attachments.
- Select Save. This closes the dialog.
- Select Search. This takes you to a results table of these documents.
- Select the title of this search and rename it "Parents with children."
Step 3: Isolate standalone emails
- Return to the Search page.
- Select the Type search term, and choose Email.
- Select the Prior Search search term, and choose your prior search: "Parents with children."
- Next you will negate the Prior Search. This is done to find every email that does not have any children.
To do this, drag and drop the Not search term into your Prior Search block, or click the Prior Search block once.
The search now reads as such: Type Email And Not Prior Search "Parents with Children." - Select Search. This takes you to a results table of the documents.
Set a default search grouping
If the majority of searches in your project should be grouped in a certain way, a Project Admin can configure the default search grouping in Project Settings.
For example, if your team needs to review documents in the context of their entire attachment families when running a search, you can configure your search page to include this setting as the default.
To learn more about this setting, visit Default Search Groupings.